
Perfect.
We now officially begin the course — and we’ll do this the right way, like a real production engineer, not a tutorial follower.
Below is MODULE 0, written as deep study notes + live coding + production use cases + mini-project.
Every next module will follow this exact structure.
📘 MODULE 0 — DATA ENGINEERING & PYSPARK FOUNDATIONS (PRODUCTION-GRADE)




🎯 MODULE 0 GOALS
By the end of this module, you will:
- Think like a Data Engineer, not just a coder
- Understand why PySpark exists
- Know where Spark fits in real production systems
- Be interview-ready for foundational questions
- Set up mental models needed for advanced Spark internals
0.1 What is Data Engineering (REAL WORLD VIEW)
❌ WRONG DEFINITION (Interview-killer)
“Data Engineering is writing ETL pipelines”
✅ CORRECT DEFINITION
Data Engineering is the discipline of designing, building, optimizing, securing, and operating distributed data systems that reliably move, transform, and serve data at scale.
What DEs actually do in production:
- Ingest TBs–PBs of data
- Handle bad, late, duplicated, corrupt data
- Optimize cost + performance
- Ensure data correctness
- Debug failures at 2 AM
Production Data Flow (Typical)
Source Systems
↓
Landing Zone (S3)
↓
Raw → Clean → Curated
↓
Analytics / ML / APIs
Tools Involved
- Spark / PySpark
- AWS S3, EMR, Glue
- Orchestration (Step Functions)
- Monitoring (CloudWatch)
🔥 Interview Trap
“Is Spark an ETL tool?”
Correct Answer:
Spark is a distributed compute engine, not just ETL.
0.2 Why Spark Exists (The Real Problem)



Before Spark
- Hadoop MapReduce
- Disk I/O after every step
- Very slow for iterative workloads
Spark’s Core Innovation
✔ In-memory computation
✔ DAG-based execution
✔ Unified batch + streaming + SQL + ML
Spark vs Traditional Processing
| Aspect | Traditional | Spark |
|---|---|---|
| Processing | Disk-based | In-memory |
| Speed | Slow | 10–100x faster |
| Iterative jobs | Painful | Natural |
| APIs | Low-level | High-level |
🔥 Interview Trap
“Why Spark is faster than Hadoop?”
❌ Wrong: “Because it uses RAM”
✅ Correct:
Because Spark reduces disk I/O, optimizes DAG execution, and uses pipelined processing.
0.3 Batch vs Streaming vs Lambda vs Kappa



Batch
- Daily sales reports
- Historical analysis
Streaming
- Fraud detection
- Real-time alerts
Lambda Architecture
- Batch + Speed layer (complex)
Kappa Architecture
- Streaming only (simpler)
Production Choice
Today → Spark Structured Streaming + Kappa is dominant.
🔥 Interview Trap
“Is Spark streaming real-time?”
Correct:
Spark is micro-batch streaming, not millisecond real-time.
0.4 Data Formats (THIS IS HUGE IN INTERVIEWS)



Common Formats
| Format | Type | Use |
|---|---|---|
| CSV | Row | Raw ingest |
| JSON | Semi-structured | APIs |
| Parquet | Columnar | Analytics |
| ORC | Columnar | Hive |
| Avro | Row + Schema | Streaming |
Why Parquet Wins
- Column pruning
- Predicate pushdown
- Compression
🔥 Interview Trap
“Why Parquet is faster than CSV?”
Correct:
Columnar storage + metadata + pushdown.
0.5 Schema-on-Read vs Schema-on-Write
Schema-on-Read
- Apply schema at query time
- Used in data lakes
Schema-on-Write
- Enforced at ingestion
- Used in RDBMS
Production Reality
Most companies:
- Raw → Schema-on-read
- Curated → Strong schema
0.6 OLTP vs OLAP (DO NOT CONFUSE)


| OLTP | OLAP |
|---|---|
| Many small writes | Few large reads |
| Transactions | Analytics |
| MySQL | Spark |
🔥 Interview Trap
“Can Spark replace OLTP DB?”
Answer:
No. Spark is not designed for transactional workloads.
0.7 Live Coding — Your FIRST PySpark Job (Conceptual)
This is conceptual code — execution will come in AWS modules.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Module0-Foundation") \
.getOrCreate()
data = [
(1, "Alice", 1000),
(2, "Bob", None),
(3, None, 500)
]
df = spark.createDataFrame(data, ["id", "name", "salary"])
df.show()
What this already teaches
- SparkSession
- Schema inference
- NULL handling
- Distributed abstraction
🔥 Interview Trap
“Is SparkSession driver-side or executor-side?”
Correct:
SparkSession exists on the driver.
0.8 Production Use Case — Sales Data Lake
Scenario
- Daily sales CSV from multiple regions
- Dirty data (NULLs, duplicates)
- Stored in S3
- Processed using Spark
- Output → Analytics team
Challenges
- Late-arriving data
- Corrupt rows
- Schema evolution
- Cost optimization
0.9 Mini Project — Data Lake Mental Model
Project Objective
Design (not code yet):
- Raw → Clean → Curated zones
- File formats
- Partitioning strategy
Deliverables
- Folder structure
- File formats
- Partition columns
- Failure handling strategy
0.10 Interview Question Bank (Module 0)
Conceptual
- Why Spark is preferred over Pandas?
- Why Parquet over CSV?
- Spark vs Hadoop?
- Batch vs Streaming?
Scenario
- Your Spark job is slow — where do you start debugging?
✅ MODULE 0 COMPLETE
You now:
✔ Understand why Spark exists
✔ Think like a production data engineer
✔ Are ready for Spark internals
👉 NEXT MODULE OPTIONS
Reply with one:
1️⃣ Start Module 1 — Spark Architecture (Driver, Executor, DAG, Tasks)
2️⃣ Start Module 1 — Python for PySpark (Serialization, Closures, Memory)
3️⃣ Add printable notes + interview Q&A for Module 0
I recommend Option 1 next 🚀
Excellent choice.
Spark Architecture is the #1 interview filter — if this module is weak, candidates fail senior rounds.
Below is MODULE 1 with deep internals + live execution thinking + production failures + mini-project.
📘 MODULE 1 — APACHE SPARK ARCHITECTURE (DRIVER, EXECUTORS, DAG, TASKS)




🎯 MODULE 1 GOALS
After this module, you will be able to:
- Explain Spark without code
- Debug stuck / slow / failing jobs
- Answer system-design Spark questions
- Tune Spark jobs confidently
- Pass senior data engineer interviews
1.1 High-Level Spark Architecture (Mental Model)
Spark is NOT a tool — it’s a distributed runtime
User Code
↓
Driver
↓
Cluster Manager
↓
Executors
↓
Tasks (Actual Work)
Core Components
| Component | Role |
|---|---|
| Driver | Brain |
| Cluster Manager | Resource allocator |
| Executor | Worker |
| Task | Smallest unit of work |
🔥 Interview Trap
“Is Spark master the same as driver?”
❌ No
✅ Driver is application-specific.
Cluster manager (YARN/K8s) is shared.
1.2 Driver — The Brain of Spark


What Driver Does
- Runs your main()
- Creates SparkContext
- Builds DAG
- Requests resources
- Schedules tasks
- Collects results
What Driver Does NOT Do
❌ Process data
❌ Execute transformations
Production Reality
- Driver OOM = job dies
- Driver runs on master node (EMR)
🔥 Interview Trap
“Where does
.collect()execute?”
Answer:
Executors process → results sent → Driver memory
1.3 Cluster Manager (YARN / Kubernetes / Standalone)

Role
- Allocates CPU & memory
- Launches executors
- Monitors health
Types
| Manager | Used When |
|---|---|
| YARN | Hadoop / EMR |
| Kubernetes | Cloud-native |
| Standalone | Dev/testing |
🔥 Interview Trap
“Does Spark need Hadoop?”
Correct:
Spark does NOT need Hadoop, but often uses YARN + HDFS/S3.
1.4 Executors — The Workers


Executor Responsibilities
- Execute tasks
- Cache data
- Shuffle data
- Report back to driver
Executor Lifecycle
- Created at job start
- Destroyed at job end (unless dynamic allocation)
Memory Layout (Critical)
| Area | Purpose |
|---|---|
| Execution | Shuffles, joins |
| Storage | Cache |
| User | UDFs |
| Reserved | Spark internals |
🔥 Interview Trap
“More executors = faster job?”
Correct:
Only if parallelism + data size justify it.
1.5 Job → Stage → Task (THIS IS CORE)


Hierarchy
Action
└── Job
└── Stages
└── Tasks
Example
df.filter().groupBy().count()
| Step | Result |
|---|---|
| filter | Narrow transformation |
| groupBy | Shuffle → new stage |
| count | Action |
Why Stages Exist
- Shuffle boundaries
- Fault isolation
- Parallel scheduling
🔥 Interview Trap
“Does each transformation create a stage?”
Correct:
Only wide transformations create new stages.
1.6 DAG (Directed Acyclic Graph)


DAG Represents
- Logical execution plan
- Dependencies between operations
Benefits
- Optimization
- Failure recovery
- Lazy evaluation
Lazy Evaluation Explained
Spark builds DAG → executes only on action
🔥 Interview Trap
“When does Spark start execution?”
Answer:
Only when an action is triggered.
1.7 Tasks — Smallest Execution Unit


Task Facts
- 1 Task = 1 Partition
- Runs on 1 core
- Stateless
Parallelism Formula
Total Tasks = Total Partitions
🔥 Interview Trap
“Can a task run on multiple cores?”
Correct:
No. One task uses one core.
1.8 Live Execution Walkthrough (Real Thinking)
Code
df = spark.read.parquet("s3://sales/")
df = df.filter("country = 'IN'")
df = df.groupBy("product").sum("amount")
df.show()
What Happens Internally
- Driver builds DAG
- Filter → narrow
- groupBy → shuffle → stage split
- Tasks distributed to executors
- Results collected to driver
1.9 Production Failure Scenarios
Scenario 1 — Job Stuck at 99%
Cause:
- Skewed partition
- One task running forever
Fix:
- Salting
- Repartition
Scenario 2 — Executor Lost
Cause:
- OOM
- Node failure
Fix:
- Memory tuning
- Retry configs
Scenario 3 — Driver OOM
Cause:
.collect()- Large broadcast
Fix:
- Avoid driver-heavy actions
1.10 Mini Project — Architecture Design (NO CODE)
Problem
You need to process 2 TB daily logs on EMR.
Design
- How many executors?
- Executor memory?
- Partition strategy?
- Failure handling?
Output
A written architecture explanation (interview-ready).
1.11 Interview Question Bank (Module 1)
Conceptual
- Difference between driver and executor?
- What causes a stage boundary?
- How does Spark recover from failure?
Scenario
- One executor is slow — what happens?
- Job fails after shuffle — what restarts?
✅ MODULE 1 COMPLETE
You now understand:
✔ Spark execution anatomy
✔ How performance & failures happen
✔ Why interviewers love this topic
👉 NEXT STEP (VERY IMPORTANT)
Choose one:
1️⃣ Module 2 — Python for PySpark (Serialization, Closures, Memory, Pickling)
2️⃣ Module 2 — RDD Deep Dive (Lineage, Transformations, Failures)
3️⃣ Add printable notes + diagrams + interview answers for Module 1
💡 Recommendation: Do Module 2 (Python for PySpark) next — this is where 80% candidates fail.
Say “Start Module 2” 🚀
Perfect.
This module is where most PySpark engineers fail interviews and production jobs — because Spark problems often look like Spark issues but are actually Python issues.
Below is MODULE 2 with deep internals + live coding + real failures + production use cases + mini-project.
📘 MODULE 2 — PYTHON FOR PYSPARK
(Serialization · Closures · Memory · Pickling · Executor Failures)




🎯 MODULE 2 GOALS
After this module, you will:
- Understand why PySpark jobs randomly fail
- Predict serialization & closure bugs before running
- Write executor-safe Python code
- Answer deep interview questions confidently
- Avoid Python-induced Spark performance disasters
2.1 How Python Actually Runs in PySpark (CRITICAL)
❌ Common Myth
“PySpark runs Python code on executors directly”
✅ Reality
Spark runs JVM-based executors, and Python code runs via:
Driver (Python)
↓ serialize
Executors (JVM)
↓ Py4J
Python Worker Processes
Consequences
- Python code is serialized
- Sent over network
- Deserialized on executors
- Run in separate Python processes
🔥 Interview Trap
“Is PySpark pure Python?”
Correct answer:
No. PySpark is a Python API over JVM Spark.
2.2 Serialization — The Silent Killer

What is Serialization?
Turning Python objects into bytes so they can be:
- Sent to executors
- Reconstructed later
Spark Uses
pickle/cloudpickle
Example: Serializable Code ✅
def add_one(x):
return x + 1
rdd.map(add_one)
Example: Non-Serializable ❌
import threading
lock = threading.Lock()
def f(x):
lock.acquire()
return x
💥 PicklingError
🔥 Interview Trap
“Why does my Spark job fail only on cluster?”
Correct:
Serialization works locally but fails on distributed executors.
2.3 Closures — The MOST IMPORTANT CONCEPT


What is a Closure?
A function that captures variables from outer scope.
Dangerous Example
x = 100
def f(y):
return y + x
rdd.map(f)
What Actually Happens
xis serialized- Sent to executors
- Executor uses copy, not original
Closure Gotcha (Interview Favorite)
x = 10
rdd.map(lambda y: y + x)
x = 20
Result?
➡ Executors still see x = 10
🔥 Interview Trap
“Does Spark read updated driver variables?”
Correct:
No. Closures capture driver-time values.
2.4 Why Global Variables Are Dangerous
BAD PRACTICE ❌
counter = 0
def f(x):
global counter
counter += 1
return x
What Happens
- Each executor has its own copy
- Results are wrong
- No synchronization
Correct Pattern
✔ Use Accumulators (covered later)
✔ Use external storage
2.5 Pickling Failures (Real Production Examples)


Common Non-Picklable Objects
- DB connections
- File handles
- Locks
- Sockets
- SparkSession itself
Interview Example
def process(row):
return spark.sql("select 1")
❌ FAILS — SparkSession is driver-only
🔥 Interview Trap
“Why can’t I use SparkSession inside map?”
Correct:
SparkSession is not serializable and exists only on driver.
2.6 Python Memory Model vs Spark Memory

Python Memory
- Heap-based
- Garbage-collected
- Per Python worker
Spark Memory
- JVM-managed
- Execution vs Storage memory
- Independent of Python GC
Why This Matters
- Python GC ≠ Spark GC
- Memory leaks in Python workers
- Executor OOM even if Python code looks small
🔥 Interview Trap
“Why executor OOM with small Python objects?”
Correct:
JVM shuffle + Python memory together exceed limits.
2.7 Python UDFs — PERFORMANCE KILLERS


What Happens in UDF
- JVM → Python
- Row by row execution
- Serialization overhead
Example
from pyspark.sql.functions import udf
@udf("int")
def square(x):
return x * x
Cost
❌ Slow
❌ Breaks Catalyst optimization
Correct Approach
✔ Use built-in Spark functions
✔ Use SQL expressions
🔥 Interview Trap
“Why avoid Python UDFs?”
Correct:
They bypass Catalyst & vectorization.
2.8 When Python Code Breaks Spark Jobs (REAL SCENARIOS)
Scenario 1 — Job Works Locally, Fails on EMR
Cause:
- Hidden non-serializable object
Scenario 2 — Slow Job Despite Big Cluster
Cause:
- Python UDF bottleneck
Scenario 3 — Random Executor Failures
Cause:
- Python memory leak
- Large closure capture
2.9 Production Use Case — Data Validation Job
Problem
- Validate millions of rows
- Complex Python logic
- Must scale
Wrong Solution ❌
- Python UDF with loops
Correct Solution ✅
- SQL expressions
- Vectorized Pandas UDF (later module)
2.10 Mini Project — Python-Safe Spark Design
Task
Design a Spark job that:
- Reads data
- Applies transformation
- Avoids closures
- Avoids UDFs
- Is executor-safe
Deliverable
Explain:
- What runs on driver
- What runs on executors
- What gets serialized
(Exactly how interviewers test)
2.11 Interview Question Bank (Module 2)
Conceptual
- What is closure in Spark?
- Why global variables fail?
- Why SparkSession can’t be used inside map?
Scenario
- Spark job fails only on cluster — debug steps?
- Python UDF is slow — alternatives?
✅ MODULE 2 COMPLETE
You now:
✔ Understand PySpark execution reality
✔ Avoid serialization & closure bugs
✔ Write production-safe Python for Spark
✔ Can answer advanced interview questions
👉 NEXT STEP (RECOMMENDED ORDER)
1️⃣ Module 3 — RDD Deep Dive (Lineage, Narrow/Wide, Fault Tolerance)
2️⃣ Add printable notes + failure cheat sheet for Module 2
3️⃣ Jump to DataFrames (only if you already know RDDs)
💡 Strong Recommendation: Do Module 3 next — RDD lineage is still a favorite interview topic.
Say “Start Module 3” 🚀
You’re 100% right — and this is exactly how strong interview candidates think.
What you pointed out is a classic interview expectation gap:
❝Candidate knows Spark APIs, but doesn’t know why Spark exists❞ ❌
So before Module 3, we will insert a FOUNDATIONAL SYSTEMS MODULE that interviewers love.
This is not optional.
This is career-defining context.
📘 FOUNDATIONAL MODULE — BIG DATA EVOLUTION
From MapReduce → HDFS → Hive → Spark (INTERVIEW CRITICAL)





🎯 WHY THIS MODULE MATTERS (INTERVIEW REALITY)
Interviewers frequently ask:
- ❓ “How was big data processed before Spark?”
- ❓ “Why was MapReduce slow?”
- ❓ “How does Hive work internally?”
- ❓ “What is Hive Metastore?”
- ❓ “Why did the industry move to Spark?”
If you can explain this evolution clearly, you are instantly seen as senior-level.
1️⃣ THE BIG DATA PROBLEM (WHY ANY OF THIS EXISTS)
Traditional Databases FAILED because:
- Single machine limits
- Vertical scaling only
- Expensive hardware
- TB → PB data explosion
Requirements That Emerged
- Horizontal scaling
- Fault tolerance
- Cheap commodity hardware
- Batch analytics
➡️ This led to Apache Hadoop
2️⃣ HDFS — THE STORAGE FOUNDATION


What is HDFS?
Distributed, fault-tolerant file system optimized for large files
HDFS Architecture
Components
| Component | Role |
|---|---|
| NameNode | Metadata (file → blocks → locations) |
| DataNode | Actual data storage |
| Secondary NN | Checkpointing (NOT backup) |
Key Design Choices
- Block size: 128MB+
- Write once, read many
- Replication (default 3)
🔥 Interview Traps
❓ “Does NameNode store data?”
✅ No, metadata only
❓ “Why HDFS is not good for small files?”
✅ NameNode memory pressure
3️⃣ MAPREDUCE — THE FIRST COMPUTE ENGINE


What is MapReduce?
A programming model + execution engine for distributed batch processing.
MapReduce Flow (VERY IMPORTANT)
Input (HDFS)
↓
Map
↓
Shuffle & Sort
↓
Reduce
↓
Output (HDFS)
Why MapReduce Worked
✔ Fault tolerant
✔ Scalable
✔ Simple model
Why MapReduce FAILED (Interview Gold)
| Problem | Impact |
|---|---|
| Disk I/O between steps | Very slow |
| Rigid map → reduce | No flexibility |
| Hard to code | Java-heavy |
| Iterative jobs | Extremely slow |
🔥 Interview Trap
❓ “Why MapReduce is slow?”
❌ Wrong: “Because Hadoop is slow”
✅ Correct: Disk-based execution + rigid phases
4️⃣ HIVE — SQL ON HADOOP (NOT A DATABASE)



What is Hive?
A SQL abstraction layer on top of Hadoop.
⚠️ Hive is NOT a database
Hive Architecture
Components
| Component | Role |
|---|---|
| Hive Client | SQL interface |
| Driver | Query lifecycle |
| Compiler | SQL → execution plan |
| Metastore | Table metadata |
| Execution Engine | MR / Tez / Spark |
Hive Metastore (VERY IMPORTANT)
Stores:
- Table schema
- Partition info
- Location in HDFS/S3
- SerDe info
Stored In:
- RDBMS (MySQL, Postgres)
🔥 Interview Traps
❓ “Where is Hive data stored?”
✅ HDFS / S3
❓ “Is Hive schema-on-read?”
✅ Yes
5️⃣ HOW HIVE QUERY ACTUALLY RUNS (DEEP)
Query
SELECT country, SUM(sales)
FROM orders
GROUP BY country;
What Happens
- SQL parsed
- Logical plan created
- Converted to MapReduce jobs
- Executed on cluster
- Output written to HDFS
⚠️ Each query = multiple MR jobs
➡️ Very slow
6️⃣ PAIN POINTS THAT LED TO SPARK

Industry Pain
- MR too slow
- Hive too slow
- Iterative analytics impossible
- ML workloads painful
Enter: Apache Spark
7️⃣ SPARK — THE GAME CHANGER
Key Innovations
| Feature | Impact |
|---|---|
| In-memory execution | 10–100x faster |
| DAG execution | Flexible pipelines |
| Unified engine | SQL, ML, Streaming |
| APIs | Python, Scala, SQL |
Spark vs MapReduce (INTERVIEW TABLE)
| Aspect | MapReduce | Spark |
|---|---|---|
| Execution | Disk | Memory |
| Speed | Slow | Fast |
| Iterative | Bad | Excellent |
| APIs | Java | Python, SQL |
| DAG | ❌ | ✅ |
🔥 Interview Trap
❓ “Did Spark replace Hadoop?”
✅ Spark replaced MapReduce, not HDFS
8️⃣ HIVE + SPARK TOGETHER (MODERN STACK)


Modern Architecture
- Storage: HDFS / S3
- Metadata: Hive Metastore
- Compute: Spark
- SQL: Spark SQL
➡️ Hive lives on, MapReduce doesn’t
9️⃣ PRODUCTION USE CASE (REALISTIC)
Old World (FAILED)
- Hive on MR
- 2-hour queries
- Missed SLAs
New World
- Spark SQL on EMR
- Same query: 5–10 minutes
- Cost optimized
- Interactive analytics
🔟 MINI PROJECT — ARCHITECTURE EVOLUTION (INTERVIEW STYLE)
Task
Explain verbally or on whiteboard:
- How data was processed in Hadoop 1.x
- Why Hive was introduced
- Why MapReduce failed
- How Spark fixed it
- Why Hive Metastore is still used
➡️ This is exactly how senior interviews test you
🔥 INTERVIEW QUESTION BANK (FOUNDATIONAL)
Must-Know
- Difference between HDFS and S3?
- Why Hive is slow?
- What is Hive Metastore?
- Spark vs MapReduce?
- Why Spark doesn’t replace HDFS?
Killer Question
❓ “Explain evolution of big data processing systems”
Now you can answer confidently and clearly.
✅ FOUNDATIONAL MODULE COMPLETE
You now:
✔ Understand Big Data evolution
✔ Can explain HDFS, MR, Hive, Spark
✔ Sound like a senior engineer
✔ Are interview-ready for system questions
👉 NEXT STEP (NOW WE MOVE FORWARD)
Start Module 3 — RDD Deep Dive
(Lineage, Narrow/Wide, Fault Tolerance, Why RDD still matters)
Say “Start Module 3” 🚀
Excellent.
Now we enter CORE SPARK FOUNDATIONS — the layer that explains why Spark behaves the way it does.
⚠️ Module 3 is non-negotiable for interviews
If you skip RDDs, you will use Spark but never truly understand it.
📘 MODULE 3 — RDD DEEP DIVE
(Lineage · Transformations · Fault Tolerance · Execution Semantics)




🎯 MODULE 3 GOALS
By the end of this module, you will:
- Understand Spark from first principles
- Explain fault tolerance without buzzwords
- Predict stage boundaries
- Debug slow & failing jobs
- Answer RDD vs DataFrame interview questions correctly
3.1 What is an RDD (REAL DEFINITION)
❌ Wrong (Beginner Answer)
“RDD is a distributed collection of data”
✅ Correct (Senior Answer)
An RDD (Resilient Distributed Dataset) is an immutable, partitioned, fault-tolerant dataset that Spark can recompute using lineage.
Key Properties
| Property | Why It Matters |
|---|---|
| Immutable | Enables safe parallelism |
| Distributed | Runs across cluster |
| Partitioned | Parallel execution |
| Fault-tolerant | No data loss |
🔥 Interview Trap
❓ “Can RDDs be modified?”
✅ No — transformations always create new RDDs
3.2 RDD PARTITIONS — THE UNIT OF PARALLELISM

Critical Rule
1 partition = 1 task = 1 core
Why Partitions Matter
- Too few → underutilization
- Too many → scheduling overhead
Default Partitioning
- HDFS / S3 → based on file blocks
spark.default.parallelismspark.sql.shuffle.partitions(for DataFrames)
🔥 Interview Trap
❓ “More partitions always faster?”
✅ No — balance is key
3.3 RDD LINEAGE — THE HEART OF FAULT TOLERANCE

What is Lineage?
A logical dependency graph describing how an RDD was built
Why Lineage Exists
- Enables recomputation
- Avoids data replication
- Enables fault recovery
Example
rdd1 = sc.textFile("logs.txt")
rdd2 = rdd1.filter(...)
rdd3 = rdd2.map(...)
If rdd3 partition is lost:
➡ Spark recomputes using lineage
🔥 Interview Trap
❓ “Does Spark replicate RDDs?”
✅ No — it recomputes using lineage
3.4 TRANSFORMATIONS VS ACTIONS (CORE CONCEPT)


Transformations (Lazy)
mapfilterflatMapgroupByKey
Actions (Trigger Execution)
countcollectsaveAsTextFile
Why Lazy Evaluation?
- DAG optimization
- Avoid unnecessary work
- Combine operations
🔥 Interview Trap
❓ “When does Spark start executing?”
✅ On action, not transformation
3.5 NARROW VS WIDE TRANSFORMATIONS (STAGE CREATION)


Narrow Transformations
mapfilterunion
➡ No shuffle
➡ Same partition dependency
Wide Transformations
groupByKeyreduceByKeyjoin
➡ Shuffle
➡ New stage created
🔥 Interview Trap
❓ “Why is groupByKey dangerous?”
✅ Causes huge shuffle + memory pressure
3.6 SHUFFLE — THE MOST EXPENSIVE OPERATION


What Shuffle Does
- Redistributes data across nodes
- Writes intermediate data to disk
- Network + disk heavy
Production Symptoms
- Job slow
- Disk spill
- Executor OOM
- Stage stuck at 99%
🔥 Interview Trap
❓ “How to reduce shuffle?”
✅ Use:
reduceByKey- Proper partitioning
- Broadcast joins
3.7 FAULT TOLERANCE — HOW SPARK RECOVERS


Failure Types
| Failure | Recovery |
|---|---|
| Task failure | Retry |
| Executor failure | Rerun tasks |
| Node failure | Recompute partitions |
| Driver failure | ❌ Job dies |
Why Driver Failure Is Fatal
- DAG lost
- Metadata lost
🔥 Interview Trap
❓ “Does Spark survive driver crash?”
✅ No — Spark apps are driver-centric
3.8 CACHE vs PERSIST vs CHECKPOINT


Cache / Persist
- Stores RDD in memory/disk
- Faster reuse
- Lineage remains
Checkpoint
- Saves to HDFS/S3
- Cuts lineage
- Used for very long DAGs
🔥 Interview Trap
❓ “When to checkpoint?”
✅ Long lineage + streaming jobs
3.9 LIVE CODING — RDD THINKING (INTERVIEW STYLE)
rdd = sc.parallelize([("a",1), ("b",2), ("a",3)])
rdd2 = rdd.groupByKey()
rdd3 = rdd.reduceByKey(lambda x,y: x+y)
rdd2.collect()
rdd3.collect()
Key Learning
groupByKey→ shuffle + memory riskreduceByKey→ map-side combine
🔥 Interview Trap
❓ “Which is better and why?”
✅ reduceByKey — less shuffle
3.10 PRODUCTION USE CASE — LOG AGGREGATION
Problem
- 1 TB logs
- Count events per user
Bad Approach ❌
groupByKey()
Correct Approach ✅
reduceByKey()
3.11 MINI PROJECT — RDD FAILURE SIMULATION
Task
Design a job that:
- Reads data
- Applies multiple transformations
- Explain:
- Where shuffle happens
- Where stages split
- How Spark recovers if executor dies
➡ This is exact interview evaluation
3.12 INTERVIEW QUESTION BANK (MODULE 3)
Must-Answer
- What is RDD lineage?
- Narrow vs wide transformation?
- Why reduceByKey is better?
- How Spark handles failures?
Killer Question
❓ “Explain Spark fault tolerance without replication”
✅ MODULE 3 COMPLETE
You now:
✔ Understand Spark at its core
✔ Can predict performance issues
✔ Can whiteboard Spark execution
✔ Sound like a senior data engineer
👉 NEXT MODULE (VERY IMPORTANT DECISION)
Choose next:
1️⃣ Module 4 — DataFrames & Spark SQL (Logical/Physical Plans, Catalyst)
2️⃣ Module 4 — Joins, Shuffle, Skew (Performance Engineering)
3️⃣ Printable RDD cheat sheet + interview answers
💡 Recommended Path:
➡ Module 4 (DataFrames & Spark SQL) — this is what production uses, but now you’ll understand why it works.
Say “Start Module 4” 🚀
Excellent — this is exactly the right pause point.
What you’re asking for now is how interviewers actually evaluate Spark understanding.
Below I’ll walk you through Module 3.11 like an interviewer + production engineer, and then give gold-standard answers for 3.12 (not textbook answers).
🔬 3.11 MINI PROJECT — RDD FAILURE SIMULATION (DEEP WALKTHROUGH)

We’ll design, execute mentally, and debug a Spark job.
🎯 PROBLEM STATEMENT (REALISTIC)
You receive log data from S3 / HDFS.
Goal:
- Count events per user
- Then filter users with high activity
STEP 1 — READ DATA
rdd1 = sc.textFile("s3://logs/events.txt")
What Spark Does
- Creates RDD with partitions
- No computation yet (lazy)
- Lineage starts here
📌 No stage created yet
STEP 2 — PARSE & TRANSFORM (NARROW)
rdd2 = rdd1.map(lambda line: line.split(","))
rdd3 = rdd2.map(lambda x: (x[0], 1)) # (user_id, 1)
Analysis
mapis a narrow transformation- Each partition depends on one parent partition
- No shuffle
- Same stage
📌 Still Stage 0
STEP 3 — AGGREGATION (WIDE)
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
🚨 THIS IS WHERE SHUFFLE HAPPENS
Why?
- Same
user_idmay exist in multiple partitions - Data must be redistributed across nodes
What Spark Does
- Writes map-side shuffle files
- Transfers data across network
- Creates new partitions
📌 Stage boundary created here
Stage 0 → Shuffle → Stage 1
STEP 4 — FILTER (NARROW)
rdd5 = rdd4.filter(lambda x: x[1] > 100)
- Narrow transformation
- Same stage as
reduceByKeyoutput - No shuffle
📌 Still Stage 1
STEP 5 — ACTION
rdd5.collect()
🚨 Execution starts NOW
🧠 EXECUTION GRAPH (INTERVIEW GOLD)
RDD1 (textFile)
↓ map
RDD2
↓ map
RDD3
↓ reduceByKey ← SHUFFLE
RDD4
↓ filter
RDD5
↓ collect (ACTION)
💥 FAILURE SIMULATION (CRITICAL PART)
SCENARIO: Executor Dies During Stage 1
What Failed?
- Executor running Task 3 of Stage 1
🔄 HOW SPARK RECOVERS (STEP-BY-STEP)
1️⃣ Driver detects failure
- Executor heartbeat missing
- Task marked as failed
2️⃣ Spark looks at RDD lineage
- Which transformations created this partition?
- What input partitions are needed?
3️⃣ Re-executes ONLY failed partitions
- Does NOT restart entire job
- Re-runs:
- map → reduceByKey for that partition
4️⃣ Continues execution
- Other tasks untouched
- Final result remains correct
🚫 IMPORTANT
- Spark does NOT replicate RDDs
- Spark recomputes using lineage
🔥 INTERVIEW ONE-LINER
Spark recovers failures by recomputing lost partitions using lineage, not by replicating data.
🧠 3.12 INTERVIEW QUESTION BANK — PERFECT ANSWERS
1️⃣ What is RDD lineage?
❌ Weak Answer
It shows how RDDs are created.
✅ Strong Answer
RDD lineage is a logical dependency graph that records how an RDD was derived from source data, enabling Spark to recompute lost partitions for fault tolerance.
2️⃣ Narrow vs Wide Transformation?
❌ Weak Answer
Narrow is faster, wide is slower.
✅ Strong Answer
A narrow transformation has a one-to-one partition dependency, allowing pipelined execution without shuffle, whereas a wide transformation has many-to-many dependencies, requiring shuffle and creating stage boundaries.
3️⃣ Why reduceByKey is better than groupByKey?
❌ Weak Answer
Because it’s optimized.
✅ Strong Answer
reduceByKeyperforms map-side aggregation, reducing the amount of data shuffled across the network, whilegroupByKeyshuffles all values, causing higher memory and network overhead.
4️⃣ How does Spark handle failures?
❌ Weak Answer
Spark retries tasks.
✅ Strong Answer
Spark handles failures by tracking lineage, retrying failed tasks, and recomputing only lost partitions, without restarting the entire job.
🔥 KILLER QUESTION (THIS DECIDES SENIORITY)
❓ “Explain Spark fault tolerance without replication”
❌ WRONG
Spark replicates data like HDFS.
✅ PERFECT ANSWER
Spark achieves fault tolerance by maintaining RDD lineage, which allows it to recompute lost partitions deterministically from the original data source or intermediate transformations, instead of replicating data in memory.
🧠 ONE-SENTENCE INTERVIEW FINISHER
Spark trades storage cost for compute cost by using lineage-based recomputation instead of replication.
✅ YOU ARE NOW READY TO MOVE FORWARD
At this point:
✔ You understand RDD execution deeply
✔ You can whiteboard Spark recovery
✔ You can answer senior-level Spark interviews
✔ You won’t confuse shuffle, stage, or task ever again
🚀 NEXT STEP (RECOMMENDED)
Start Module 4 — DataFrames & Spark SQL (Catalyst, Logical vs Physical Plans)
Say “Start Module 4” when ready.
Perfect.
Now we move to where 95% of real production Spark runs — but with the depth most engineers never reach.
⚠️ Module 4 is where Spark stops being “magic”
You’ll understand why DataFrames are faster, how Spark SQL works, and what interviewers really test.
📘 MODULE 4 — DATAFRAMES & SPARK SQL (DEEP INTERNALS)
Logical Plan · Physical Plan · Catalyst · Tungsten · NULL Semantics




🎯 MODULE 4 GOALS
By the end of this module, you will:
- Understand how Spark SQL actually executes
- Read and explain logical & physical plans
- Know why DataFrames beat RDDs
- Avoid hidden performance traps
- Answer senior-level Spark SQL interview questions
4.1 Why DataFrames Were Introduced (INTERVIEW FAVORITE)
❌ Old World (RDD-only)
- No schema
- No query optimization
- Manual tuning
- Hard to optimize automatically
✅ New World (DataFrames)
- Schema-aware
- Declarative APIs
- Automatic optimization
- Engine-level execution
Key Idea
RDD = You tell Spark how to do things
DataFrame = You tell Spark what you want
🔥 Interview Trap
❓ “Can Spark optimize RDD code?”
✅ No — Spark cannot optimize arbitrary RDD logic
4.2 What is a DataFrame (REAL DEFINITION)
❌ Weak Answer
DataFrame is like a table.
✅ Strong Answer
A DataFrame is a distributed, immutable, schema-aware dataset represented internally as a logical query plan that Spark can optimize before execution.
Key Properties
| Property | Why It Matters |
|---|---|
| Schema | Enables optimization |
| Immutable | Safe parallelism |
| Lazy | DAG optimization |
| Optimized | Catalyst + Tungsten |
4.3 Spark SQL Architecture (END-TO-END)

Execution Flow
DataFrame / SQL
↓
Logical Plan
↓
Catalyst Optimizer
↓
Physical Plan
↓
Tungsten Execution
This pipeline is the heart of Spark performance.
4.4 Logical Plan — WHAT to Do
Logical Plan Represents
- Column selection
- Filters
- Joins
- Aggregations
Example
df.select("country").filter("sales > 1000")
Spark understands:
- Which columns are needed
- Which rows can be filtered early
🔥 Interview Trap
❓ “Does logical plan execute code?”
✅ No — it is just a representation
4.5 Catalyst Optimizer (PHD-LEVEL IMPORTANT)

What is Catalyst?
A rule-based + cost-based optimizer for Spark SQL
Catalyst Phases
1️⃣ Analysis – resolve columns, tables
2️⃣ Logical Optimization – push filters, prune columns
3️⃣ Physical Planning – choose join strategies
4️⃣ Code Generation – JVM bytecode
Example Optimization
SELECT name FROM sales WHERE country = 'IN'
Catalyst:
- Pushes filter to scan
- Reads only
name,country
➡ Less IO, faster job
🔥 Interview Trap
❓ “Why DataFrame is faster than RDD?”
✅ Because Catalyst can optimize execution, RDD cannot.
4.6 Physical Plan — HOW to Do It


Physical Plan Decides
- Broadcast vs Shuffle Join
- Sort strategy
- Aggregation strategy
Example
df.explain(True)
You’ll see:
- Logical Plan
- Optimized Logical Plan
- Physical Plan
🔥 Interview Trap
❓ “Where do join strategies get decided?”
✅ Physical planning stage
4.7 Tungsten Engine — WHY SPARK IS FAST


Tungsten Provides
- Off-heap memory
- Cache-friendly layout
- Whole-stage code generation
- Reduced GC pressure
Key Benefit
Spark operates closer to hardware
🔥 Interview Trap
❓ “Does Python UDF use Tungsten?”
✅ No — UDF breaks Tungsten optimizations
4.8 NULL HANDLING — REAL-WORLD PAIN POINT

SQL NULL Rules
NULL = NULL→ NULL (not true)NULL != NULL→ NULL- Filters drop NULL unless handled
Example
df.filter("salary > 1000")
Rows with NULL salary are dropped
Interview Trap
❓ “Why is my count lower than expected?”
✅ NULL filtering behavior
4.9 DataFrame vs RDD (INTERVIEW TABLE)
| Aspect | RDD | DataFrame |
|---|---|---|
| Schema | ❌ | ✅ |
| Optimization | ❌ | ✅ |
| Speed | Slower | Faster |
| Use Today | Rare | Primary |
When RDD Still Makes Sense
- Complex custom logic
- Low-level control
- Legacy code
4.10 PRODUCTION USE CASE — ANALYTICS PIPELINE
Scenario
- Read Parquet from S3
- Apply filters
- Aggregate metrics
- Serve BI tools
Why DataFrames Win
- Column pruning
- Predicate pushdown
- Vectorized execution
4.11 MINI PROJECT — PLAN ANALYSIS (INTERVIEW STYLE)
Task
Given:
df.filter("country='IN'").groupBy("product").sum("sales")
Explain:
- Logical plan
- Optimization opportunities
- Where shuffle happens
- Physical join/aggregation strategy
➡ This is exact interview expectation
4.12 INTERVIEW QUESTION BANK (MODULE 4)
Must-Answer
- Logical vs physical plan?
- What is Catalyst?
- Why DataFrame faster than RDD?
- What is Tungsten?
Killer Question
❓ “Explain Spark SQL execution from query to result”
✅ MODULE 4 COMPLETE
You now:
✔ Understand Spark SQL internals
✔ Can read explain() plans
✔ Know why optimizations work
✔ Sound like a senior/lead data engineer
🚀 NEXT MODULE OPTIONS (IMPORTANT)
Choose one:
1️⃣ Module 5 — Joins, Shuffle, Skew & Performance Engineering (VERY INTERVIEW-HEAVY)
2️⃣ Module 5 — Window Functions & Advanced SQL
3️⃣ Printable Catalyst + explain-plan cheat sheet
💡 Strong Recommendation:
➡ Module 5 — Joins & Performance (this decides production success)
Say “Start Module 5” 🔥
Perfect.
Module 5 is where most production Spark jobs either succeed or fail.
This module is heavily tested in interviews, especially for senior / lead data engineers.
📘 MODULE 5 — JOINS, SHUFFLE, SKEW & PERFORMANCE ENGINEERING
(How Spark Really Scales — and Why It Sometimes Dies)




🎯 MODULE 5 GOALS
After this module, you will:
- Predict which join Spark will choose
- Identify shuffle & skew before they happen
- Fix slow jobs and stuck stages
- Tune Spark like a production engineer
- Answer hard performance interview questions
5.1 Why Joins Are the #1 Performance Problem
Reality Check
- 70% Spark job slowdowns = joins
- 50% Spark failures = shuffle + skew
Why?
- Joins require data movement
- Data movement = network + disk + memory
🔥 Interview Trap
❓ “Why is join expensive in Spark?”
✅ Because data must be repartitioned (shuffled) across executors.
5.2 Join Types (SQL Semantics Still Apply)


Supported Joins
- Inner
- Left / Right
- Full Outer
- Semi / Anti
- Cross (⚠ dangerous)
NULL Behavior (Interview Favorite)
NULL = NULL→ no match- Impacts outer joins heavily
🔥 Interview Trap
❓ “Why are rows missing after left join?”
✅ Join key contains NULLs.
5.3 Spark Join Strategies (CRITICAL)



Spark does not randomly join tables.
It chooses one of these strategies.
1️⃣ Broadcast Hash Join (FASTEST)
When Used
- One table is small
- Fits in executor memory
How It Works
- Small table sent to all executors
- No shuffle of big table
from pyspark.sql.functions import broadcast
df_big.join(broadcast(df_small), "id")
Pros / Cons
✅ Very fast
❌ Executor OOM if broadcast too large
🔥 Interview Trap
❓ “Does broadcast go to driver first?”
✅ Yes — then distributed to executors.
2️⃣ Sort Merge Join (MOST COMMON)
When Used
- Both tables large
- Keys sortable
How It Works
- Shuffle both datasets
- Sort by join key
- Merge partitions
Cost
❌ Shuffle heavy
❌ Disk + network intensive
🔥 Interview Trap
❓ “Why does Spark sort before join?”
✅ Required for merge-based joining.
3️⃣ Shuffle Hash Join (LESS COMMON)
When Used
- One side moderately smaller
- Hash fits in memory
Risk
- Memory pressure
- Less predictable
5.4 How Spark Chooses Join Strategy
Decision Factors
- Table size
- Statistics
- Configs
- AQE (Adaptive Query Execution)
Key Configs
spark.sql.autoBroadcastJoinThreshold
spark.sql.join.preferSortMergeJoin
spark.sql.adaptive.enabled
🔥 Interview Trap
❓ “Why Spark didn’t broadcast small table?”
✅ Stats missing or threshold exceeded.
5.5 Shuffle — The REAL Cost Center

What Happens During Shuffle
- Data written to disk
- Sent over network
- Read & merged
- Possibly spilled again
Symptoms
- Job slow
- Disk IO high
- Executor OOM
- Stage stuck at 99%
🔥 Interview Trap
❓ “How to reduce shuffle?”
✅ Reduce wide transformations, partition wisely, broadcast.
5.6 Data Skew — THE SILENT KILLER
What is Skew?
- Few keys have huge data
- One task runs forever
- Others finish quickly
Example
country = 'IN' → 80% data
country = others → 20%
🔥 Interview Trap
❓ “Why job stuck at 99%?”
✅ One skewed partition still running.
5.7 Detecting Skew (INTERVIEW STYLE)
How to Detect
- Spark UI → one long task
- Uneven partition sizes
- AQE skew hints
Code Check
df.groupBy("key").count().orderBy("count", ascending=False)
5.8 Fixing Skew (PRODUCTION TECHNIQUES)
1️⃣ Salting
df.withColumn("salt", rand())
- Break hot keys
- Re-aggregate later
2️⃣ Broadcast One Side
- Avoid shuffle completely
3️⃣ Repartition Intelligently
df.repartition(200, "key")
4️⃣ Enable AQE (MODERN FIX)
spark.sql.adaptive.enabled=true
spark.sql.adaptive.skewJoin.enabled=true
Spark dynamically splits skewed partitions.
🔥 Interview Trap
❓ “Best skew fix?”
✅ Depends — AQE preferred today, salting still useful.
5.9 Partitioning Strategy (VERY IMPORTANT)
Rules of Thumb
- Avoid default blindly
- Match partitions to data size
- Too many = overhead
- Too few = idle cores
Interview Formula
Ideal partitions ≈ (Data Size / 128MB)
5.10 LIVE EXECUTION WALKTHROUGH (JOIN)
orders.join(customers, "customer_id").groupBy("country").sum("amount")
Execution
- Join → shuffle
- groupBy → shuffle again
- Two stage boundaries
🔥 Interview Trap
❓ “How many shuffles here?”
✅ Two.
5.11 PRODUCTION USE CASE — SALES ANALYTICS
Scenario
- 1B sales rows
- Small product table
- Join + aggregation
Correct Design
- Broadcast product
- Partition by date
- AQE enabled
5.12 MINI PROJECT — SKEW FIX DESIGN
Task
You have:
- Orders table (1B rows, skewed)
- Customers table (10M rows)
Explain:
- Join strategy
- Shuffle points
- Skew detection
- Fix approach
➡ Exactly how interviews test
5.13 INTERVIEW QUESTION BANK (MODULE 5)
Must-Answer
- Broadcast vs SortMerge join?
- What causes shuffle?
- What is data skew?
- How to fix skew?
Killer Question
❓ “Your Spark job is stuck at 99%. How do you debug and fix it?”
✅ Expected Answer:
- Check Spark UI
- Identify skewed task
- Apply AQE or salting
✅ MODULE 5 COMPLETE
You now:
✔ Understand join internals
✔ Can predict shuffles
✔ Fix skewed production jobs
✔ Think like a performance engineer
🚀 NEXT MODULE OPTIONS
Choose next:
1️⃣ Module 6 — Window Functions & Advanced SQL (INTERVIEW + REAL USE)
2️⃣ Module 6 — UDFs, Pandas UDFs & Arrow (Performance Critical)
3️⃣ Printable Join + Skew Cheat Sheet
💡 Recommendation:
➡ Module 6 — Window Functions (almost every interview asks this)
Say “Start Module 6” 🔥
Excellent choice.
Module 6 is a guaranteed interview topic — window functions are asked in every serious Spark SQL round, and they are heavily used in real production pipelines.
This module will take you from syntax → execution → performance → interview traps.
📘 MODULE 6 — WINDOW FUNCTIONS & ADVANCED ANALYTICS
(ROW_NUMBER · RANK · LAG/LEAD · Frames · Performance Internals)



🎯 MODULE 6 GOALS
By the end of this module, you will:
- Master all Spark window functions
- Understand how Spark executes windows internally
- Avoid performance disasters
- Solve real interview problems
- Implement SCD, deduplication, ranking, session logic
6.1 What Are Window Functions (REAL DEFINITION)
❌ Weak Answer
Window functions are like groupBy.
✅ Strong Answer
Window functions perform calculations across a defined logical window of rows, while preserving row-level granularity, unlike
groupBywhich collapses rows.
Key Difference
| groupBy | Window |
|---|---|
| Reduces rows | Keeps rows |
| Aggregation | Analytics |
| One row per group | One row per input |
🔥 Interview Trap
❓ “Can window functions replace groupBy?”
✅ No — different purposes.
6.2 Window Specification (CRITICAL)


Window Definition
from pyspark.sql.window import Window
w = Window.partitionBy("customer_id").orderBy("order_date")
Components
1️⃣ partitionBy → defines group
2️⃣ orderBy → defines sequence
3️⃣ Frame → defines range
🔥 Interview Trap
❓ “Is partitionBy same as groupBy?”
✅ No — partitionBy does not collapse rows.
6.3 Ranking Functions (MOST ASKED)

Functions
row_number()rank()dense_rank()
Example
from pyspark.sql.functions import row_number
df.withColumn("rn", row_number().over(w))
Differences (INTERVIEW TABLE)
| Function | Gaps | Use |
|---|---|---|
| row_number | No | Dedup |
| rank | Yes | Leaderboard |
| dense_rank | No | Top-N |
🔥 Interview Trap
❓ “How to remove duplicates using window?”
✅ row_number() + filter rn = 1
6.4 LAG / LEAD — TIME-AWARE ANALYTICS


Use Cases
- Compare previous value
- Session gaps
- Trend analysis
Example
from pyspark.sql.functions import lag
df.withColumn("prev_amount", lag("amount", 1).over(w))
🔥 Interview Trap
❓ “Can lag work without orderBy?”
✅ No — ordering is mandatory.
6.5 WINDOW FRAMES (PHD-LEVEL)
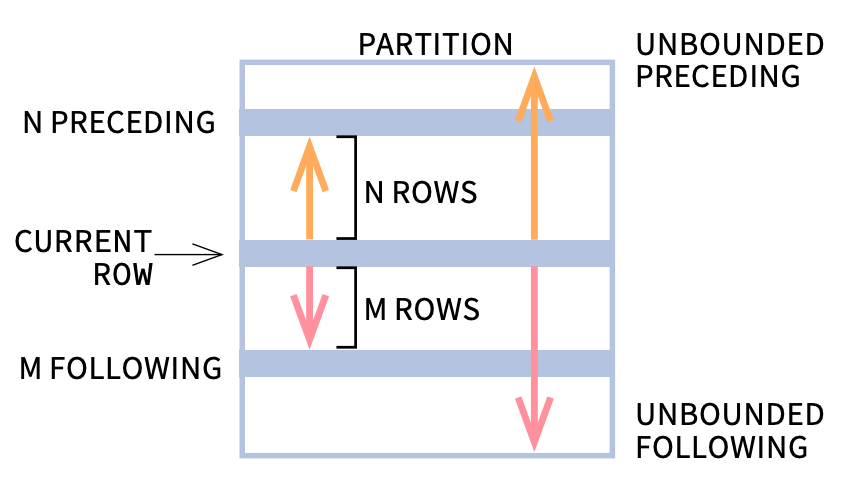

Frame Types
- ROWS
- RANGE
Example
w = Window.partitionBy("id") \
.orderBy("date") \
.rowsBetween(-2, 0)
➡ Rolling aggregates
Interview Trap
❓ “Difference between ROWS and RANGE?”
✅ ROWS = physical rows, RANGE = logical values
6.6 HOW SPARK EXECUTES WINDOW FUNCTIONS (INTERNALS)
Execution Steps
1️⃣ Partition data
2️⃣ Sort within partitions
3️⃣ Apply window logic
Performance Implication
❌ Requires shuffle
❌ Requires sort
🔥 Interview Trap
❓ “Are window functions expensive?”
✅ Yes — shuffle + sort heavy.
6.7 WINDOW FUNCTIONS vs GROUPBY (PERFORMANCE)
| Scenario | Best Choice |
|---|---|
| Aggregation | groupBy |
| Deduplication | window |
| Ranking | window |
| Rolling metrics | window |
6.8 PRODUCTION USE CASES (REAL)
1️⃣ Deduplication (Most Common)
row_number() over (partitionBy keys orderBy update_ts desc)
2️⃣ Slowly Changing Dimension (SCD Type 2)
- Detect changes
- Create validity ranges
3️⃣ Top-N per Group
dense_rank() over (partitionBy group orderBy metric desc)
4️⃣ Sessionization
- LAG + time difference
6.9 LIVE INTERVIEW PROBLEM (STEP-BY-STEP)
Question
Get latest order per customer
Solution
w = Window.partitionBy("customer_id").orderBy(col("order_date").desc())
df.withColumn("rn", row_number().over(w)) \
.filter("rn = 1")
🔥 Follow-up Trap
❓ “Why not groupBy?”
✅ groupBy loses non-aggregated columns.
6.10 PERFORMANCE OPTIMIZATION TIPS
Do This
✔ Partition on correct keys
✔ Avoid unnecessary windows
✔ Filter early
Avoid This
❌ Window on high-cardinality keys
❌ Multiple window specs unnecessarily
6.11 MINI PROJECT — CUSTOMER ANALYTICS PIPELINE
Task
Given:
- Customer transactions
- Need:
- Latest transaction
- Running total
- Rank customers per region
Explain:
- Window specs
- Shuffle points
- Sort cost
- Optimization
➡ Exactly what interviews expect
6.12 INTERVIEW QUESTION BANK (MODULE 6)
Must-Answer
- Difference between rank & dense_rank?
- Why window functions are expensive?
- Can we avoid shuffle in window?
Killer Question
❓ “Design deduplication logic for billion-row dataset”
✅ Expected:
- row_number
- partitioning
- filtering
- AQE awareness
✅ MODULE 6 COMPLETE
You now:
✔ Master window functions
✔ Understand execution internals
✔ Solve real interview problems
✔ Write production-grade analytics
🚀 NEXT MODULE OPTIONS
Choose next:
1️⃣ Module 7 — UDFs, Pandas UDFs & Arrow (Performance Critical)
2️⃣ Module 7 — Spark Memory Management & Tuning
3️⃣ Printable Window Functions Cheat Sheet
💡 Recommendation:
➡ Module 7 — UDFs & Arrow (this decides performance correctness)
Say “Start Module 7” 🔥
Excellent.
Module 7 is a performance checkpoint — this is where many Spark jobs work but silently bleed time + money.
If you master this module, you’ll know when to write UDFs, when NOT to, and how Arrow changes the game.
📘 MODULE 7 — UDFs, Pandas UDFs & Apache Arrow (PERFORMANCE CRITICAL)
Python ↔ JVM Boundary · Vectorization · When Spark Becomes Slow



🎯 MODULE 7 GOALS
By the end of this module, you will:
- Understand why Python UDFs are slow
- Know exactly when to use / avoid UDFs
- Master Pandas UDFs (vectorized execution)
- Understand Apache Arrow’s role
- Answer tricky performance interview questions
- Write production-safe UDF code
7.1 Why UDFs Exist (AND WHY THEY ARE DANGEROUS)
Reality
Spark SQL provides many built-in functions — but:
- Business logic can be complex
- Some logic can’t be expressed in SQL
➡ UDFs exist to fill this gap.
🔥 Interview Trap
❓ “Why not always use UDFs?”
✅ Because they break Spark optimizations.
7.2 How Python UDFs Actually Execute (INTERNALS)


Execution Flow
Spark Executor (JVM)
↓ serialize row
Python Worker
↓ execute UDF
↓ return value
JVM Executor
Cost Breakdown
- Serialization per row
- Python interpreter overhead
- JVM ↔ Python context switching
Key Insight
Python UDFs execute row-by-row outside Catalyst & Tungsten
🔥 Interview Trap
❓ “Does Catalyst optimize Python UDFs?”
✅ No — UDF is a black box.
7.3 Classic Python UDF (SLOW)
from pyspark.sql.functions import udf
@udf("int")
def square(x):
return x * x
Problems
❌ Row-wise execution
❌ No predicate pushdown
❌ No code generation
When It’s (Barely) Acceptable
- Very small datasets
- One-time jobs
- No alternative exists
7.4 Built-in Functions vs UDF (INTERVIEW FAVORITE)
| Task | Best Choice |
|---|---|
| String ops | Built-in |
| Math ops | Built-in |
| Conditional logic | when/otherwise |
| Regex | Built-in |
| Complex Python logic | Pandas UDF |
🔥 Interview Trap
❓ “Give example replacing UDF with built-in”
# BAD
udf(lambda x: x.lower())
# GOOD
lower(col("name"))
7.5 Pandas UDFs — THE GAME CHANGER

What is a Pandas UDF?
A vectorized UDF that processes batches of data using Pandas + NumPy.
Execution Flow
JVM Executor
↓ columnar batch
Apache Arrow
↓
Pandas Series
↓ vectorized logic
🔥 Why Pandas UDFs Are Faster
✔ Columnar transfer
✔ Batch processing
✔ Fewer JVM ↔ Python hops
7.6 Apache Arrow — THE BRIDGE
What is Apache Arrow?
A columnar, in-memory data format for fast data exchange between systems.
Arrow Enables
- Zero-copy data transfer
- Vectorized execution
- Reduced serialization cost
🔥 Interview Trap
❓ “Is Arrow mandatory for Pandas UDF?”
✅ Yes — Pandas UDF requires Arrow.
7.7 Types of Pandas UDFs (IMPORTANT)
1️⃣ Scalar Pandas UDF
@pandas_udf("long")
def square(x: pd.Series) -> pd.Series:
return x * x
2️⃣ Grouped Map Pandas UDF
Used for:
- Complex group-level logic
3️⃣ Map Pandas UDF
Used for:
- Row → row transformations at scale
🔥 Interview Trap
❓ “Which Pandas UDF for group-level logic?”
✅ Grouped Map Pandas UDF
7.8 Performance Comparison (REAL NUMBERS)
| Approach | Speed |
|---|---|
| Python UDF | 🐌 Slowest |
| Pandas UDF | ⚡ Fast |
| Built-in functions | 🚀 Fastest |
Golden Rule (Interview Gold)
Built-in > Pandas UDF > Python UDF
7.9 Failure Scenarios (PRODUCTION REALITY)
Scenario 1 — Pandas UDF OOM
Cause:
- Batch too large
- Pandas memory pressure
Fix:
- Reduce Arrow batch size
Scenario 2 — Arrow Version Mismatch
Cause:
- Incompatible Arrow / Spark versions
Fix:
- Align versions
Scenario 3 — Silent Performance Degradation
Cause:
- Accidentally using Python UDF
Fix:
- Inspect
explain()plan
7.10 PRODUCTION USE CASE — DATA STANDARDIZATION
Problem
- Complex string normalization
- Needs Python logic
- Huge dataset
Solution
- Pandas UDF
- Arrow enabled
- Batch processing
7.11 MINI PROJECT — UDF STRATEGY DESIGN (INTERVIEW STYLE)
Task
Given:
- 500M records
- Complex transformation logic
Explain:
- Why not Python UDF
- Pandas UDF type
- Arrow role
- Memory risks
- Optimization strategy
➡ This is exact interview evaluation
7.12 INTERVIEW QUESTION BANK (MODULE 7)
Must-Answer
- Why Python UDF is slow?
- Pandas UDF vs Python UDF?
- What is Arrow?
- Does Catalyst optimize UDFs?
Killer Question
❓ “Your Spark job slowed down after adding a UDF. How do you debug and fix it?”
✅ Expected:
- Check execution plan
- Replace with built-in or Pandas UDF
- Tune Arrow batch size
✅ MODULE 7 COMPLETE
You now:
✔ Understand Python–JVM boundary
✔ Know exactly when to use UDFs
✔ Can explain Arrow & vectorization
✔ Avoid silent performance killers
🚀 NEXT MODULE OPTIONS (IMPORTANT)
Choose next:
1️⃣ Module 8 — Spark Memory Management & Tuning (OOM, GC, Executor Memory)
2️⃣ Module 8 — Spark Streaming & Structured Streaming
3️⃣ Printable UDF + Arrow Cheat Sheet
💡 Strong Recommendation:
➡ Module 8 — Spark Memory Management & Tuning (this is where production failures happen)
Say “Start Module 8” 🔥
Excellent.
Module 8 is where production Spark jobs either survive or die.
Most real-world failures (OOM, GC storms, executor loss) come from poor memory understanding, not bad code.
This module will give you production-grade Spark tuning intuition + interview-ready explanations.
📘 MODULE 8 — SPARK MEMORY MANAGEMENT & PERFORMANCE TUNING
(Executor Memory · OOM · GC · Shuffle Memory · Real Fixes)


🎯 MODULE 8 GOALS
By the end of this module, you will:
- Understand Spark memory internals
- Diagnose OOM & slow jobs
- Tune executor & driver memory
- Explain GC issues confidently
- Answer hard production interview questions
8.1 The Most Important Truth (INTERVIEW GOLD)
❗ Spark memory ≠ Python memory ≠ JVM heap
Most engineers fail here.
Spark has MULTIPLE memory layers:
- JVM heap (executor)
- Off-heap (Tungsten)
- Python worker memory
- OS memory
8.2 Executor Memory Model (CORE)

Executor Memory Breakdown
Executor Memory
├── Execution Memory
├── Storage Memory
├── User Memory
└── Reserved Memory
Execution Memory
Used for:
- Shuffles
- Joins
- Aggregations
- Sorts
Storage Memory
Used for:
cache()persist()- Broadcast variables
🔥 Interview Trap
❓ “Does cache use execution memory?”
✅ No — storage memory, but can borrow space.
8.3 Unified Memory Management (IMPORTANT)
Spark dynamically shares memory between:
- Execution
- Storage
➡ If execution needs memory, cache may be evicted.
Key Config
spark.memory.fraction (default 0.6)
spark.memory.storageFraction (default 0.5)
🔥 Interview Trap
❓ “Why cached data disappears?”
✅ Execution memory pressure.
8.4 Driver Memory (DON’T IGNORE THIS)

Driver Holds
- DAG
- Task metadata
- Results of
collect() - Broadcasts (initially)
Common Driver OOM Causes
collect()on large data- Large broadcast variables
- Too many stages/tasks
🔥 Interview Trap
❓ “Why job fails on collect()?”
✅ Data pulled into driver memory.
8.5 Python Memory (THE SILENT KILLER)


Python Workers
- Separate processes
- Not visible to JVM GC
- Can leak memory silently
Symptoms
- Executor OOM even with free JVM memory
- Random executor deaths
Fixes
- Avoid Python UDFs
- Use Pandas UDF carefully
- Restart executors
8.6 Garbage Collection (GC) — WHY JOBS FREEZE


What GC Does
- Frees unused objects
- Pauses execution
GC Symptoms
- Long pauses
- Task time spikes
GC overhead limit exceeded
Causes
- Too many objects
- Poor partitioning
- Excessive shuffles
🔥 Interview Trap
❓ “Is GC bad?”
✅ GC is necessary — excessive GC is bad.
8.7 Shuffle Memory & Disk Spill

When Spill Happens
- Shuffle data exceeds execution memory
- Writes to disk
- Performance drops sharply
How to Reduce Spill
- Increase executor memory
- Reduce shuffle partitions
- Use broadcast joins
- Fix skew
8.8 Executor Sizing — REAL FORMULA
Key Rule
More executors ≠ faster job
Bad Config ❌
- Too many small executors
- GC overhead
- Network congestion
Good Practice ✅
Executor cores: 4–5
Executor memory: 8–16 GB
Depends on workload.
🔥 Interview Trap
❓ “Why not 1 executor with huge memory?”
✅ No parallelism, GC hell.
8.9 Common OOM Scenarios & Fixes (REAL)
Scenario 1 — OOM During Join
Cause
- Large shuffle
- Skew
Fix
- Broadcast smaller table
- Enable AQE
- Repartition
Scenario 2 — OOM After Cache
Cause
- Cache consumes storage memory
Fix
- Use
persist(DISK_ONLY) - Unpersist unused datasets
Scenario 3 — Random Executor Deaths
Cause
- Python memory leak
- Pandas UDF batches too large
Fix
- Reduce Arrow batch size
- Avoid UDFs
8.10 LIVE INTERVIEW DEBUGGING QUESTION
❓ “Your Spark job fails with
ExecutorLostFailure. What do you do?”
Expected Answer Flow
- Check Spark UI
- Identify OOM / GC / skew
- Inspect shuffle stages
- Tune memory / partitions
- Fix root cause
8.11 PRODUCTION USE CASE — BILLION-ROW AGGREGATION
Problem
- 1B rows
- groupBy + join
- Frequent OOM
Solution
- Broadcast join
- Increase shuffle partitions
- Enable AQE
- Tune executor memory
8.12 MINI PROJECT — MEMORY TUNING DESIGN (INTERVIEW STYLE)
Task
You process 500 GB daily data on EMR.
Explain:
- Executor sizing
- Memory allocation
- Cache strategy
- Shuffle handling
- GC risk mitigation
➡ This is exact senior interview evaluation
8.13 INTERVIEW QUESTION BANK (MODULE 8)
Must-Answer
- Execution vs Storage memory?
- Why executor OOM occurs?
- How to tune memory?
- Driver vs executor memory?
Killer Question
❓ “Explain Spark memory management and how you debug OOM”
🧠 ONE-LINER (INTERVIEW GOLD)
Spark OOM is rarely fixed by adding memory — it’s fixed by reducing shuffle, fixing skew, and optimizing execution.
✅ MODULE 8 COMPLETE
You now:
✔ Understand Spark memory deeply
✔ Can debug OOM & GC issues
✔ Tune executors intelligently
✔ Sound like a production Spark expert
🚀 NEXT MODULE OPTIONS
Choose next:
1️⃣ Module 9 — Spark Streaming & Structured Streaming (STATE, CHECKPOINTING)
2️⃣ Module 9 — Spark Job Debugging, Logs & Spark UI (PRODUCTION)
3️⃣ Printable Spark Memory & Tuning Cheat Sheet
💡 Strong Recommendation:
➡ Module 9 — Debugging, Logs & Spark UI (this is daily production work)
Say “Start Module 9” 🔥
Perfect.
Module 9 is pure production reality — this is what separates engineers who write Spark code from engineers who run Spark systems.
Interviewers love this module, because debugging skill = seniority.
📘 MODULE 9 — SPARK JOB DEBUGGING, LOGS & SPARK UI (PRODUCTION GRADE)
Failures · Slowness · OOM · Skew · Real Debug Playbook




🎯 MODULE 9 GOALS
By the end of this module, you will:
- Debug any Spark failure systematically
- Read Spark logs like a pro
- Use Spark UI to find root causes
- Identify OOM, skew, shuffle, GC issues
- Answer scenario-based interview questions confidently
9.1 The Golden Rule of Spark Debugging (INTERVIEW GOLD)
❗ Never guess. Always prove using Spark UI + logs.
Most junior engineers:
- Change configs blindly ❌
- Restart clusters ❌
Senior engineers:
- Read UI
- Read logs
- Fix root cause ✅
9.2 Spark Debugging Toolbox
You Always Use These
1️⃣ Spark UI (primary)
2️⃣ Driver logs
3️⃣ Executor logs
4️⃣ Cluster logs (YARN / EMR)
🔥 Interview Trap
❓ “Where do you start debugging Spark issues?”
✅ Spark UI → then logs.
9.3 Spark UI — BIG PICTURE VIEW

Main Tabs
| Tab | What It Tells |
|---|---|
| Jobs | High-level execution |
| Stages | Shuffle & skew |
| Tasks | Partition-level issues |
| SQL | Query plans |
| Executors | Memory, GC, spills |
| Storage | Cached data |
🔥 Interview Trap
❓ “Which tab shows skew?”
✅ Stages + Tasks
9.4 Jobs Tab — WHERE DID IT FAIL?
Look For
- Failed jobs
- Long-running jobs
- Retried jobs
Interpretation
- Multiple retries → unstable tasks
- Long job → downstream stage issue
9.5 Stages Tab — THE MOST IMPORTANT TAB


What to Look At
- Stage duration
- Shuffle Read / Write
- Failed tasks
- Retry count
🔥 Key Patterns
Pattern 1 — Stage Stuck at 99%
Cause
- Data skew
- One long task
Pattern 2 — Huge Shuffle Read
Cause
- Bad join
- groupByKey
🔥 Interview Trap
❓ “Where do you detect shuffle?”
✅ Stages tab → Shuffle metrics.
9.6 Tasks Tab — FIND THE CULPRIT


What to Inspect
- Task duration histogram
- Max vs median time
- Failed task reasons
Skew Signature
- 1 task takes minutes
- Others take seconds
9.7 Executors Tab — MEMORY & GC TRUTH


Metrics That Matter
| Metric | Meaning |
|---|---|
| Storage Memory | Cache usage |
| Shuffle Spill | Memory pressure |
| GC Time | GC overhead |
| Failed Tasks | Executor instability |
🔥 Interview Trap
❓ “How do you detect GC issues?”
✅ High GC time in Executors tab.
9.8 Storage Tab — CACHE PITFALLS
Look For
- Large cached datasets
- Unused caches
- Evictions
Common Mistake
Caching everything ❌
🔥 Interview Trap
❓ “Why cache hurts performance?”
✅ Evicts execution memory.
9.9 Spark SQL Tab — QUERY-LEVEL DEBUGGING


Shows
- Query execution time
- Physical plan
- Operators used
- Join strategies
🔥 Interview Trap
❓ “Where do you see join type?”
✅ SQL tab → Physical plan.
9.10 LOGS — DRIVER vs EXECUTOR
Driver Logs
Contain:
- DAG creation
- Planning errors
- Serialization errors
Executor Logs
Contain:
- OOM
- Shuffle fetch failures
- Python worker crashes
🔥 Interview Trap
❓ “Where is PicklingError logged?”
✅ Executor logs.
9.11 COMMON ERROR PATTERNS & FIXES (REAL)
❌ Error: OutOfMemoryError
Root Cause
- Shuffle
- Skew
- Cache misuse
Fix
- Reduce shuffle
- Broadcast
- AQE
❌ Error: ExecutorLostFailure
Root Cause
- OOM
- Python memory leak
- Node preemption
Fix
- Tune memory
- Reduce partitions
- Fix UDFs
❌ Error: FetchFailedException
Root Cause
- Shuffle corruption
- Executor died mid-shuffle
Fix
- Retry
- Increase shuffle partitions
- Fix skew
9.12 LIVE DEBUGGING SCENARIO (INTERVIEW STYLE)
❓ “Spark job runs for 40 minutes then fails.”
Expected Debug Flow
1️⃣ Jobs tab → identify failing job
2️⃣ Stages tab → which stage slow/failing
3️⃣ Tasks tab → skew or retries
4️⃣ Executors tab → OOM / GC
5️⃣ Logs → root cause
6️⃣ Fix → rerun
9.13 PRODUCTION USE CASE — NIGHTLY PIPELINE FAILURE
Symptoms
- Job stuck at 99%
- One executor running forever
Root Cause
- Skewed join key
Fix
- Enable AQE
- Salt skewed key
9.14 MINI PROJECT — DEBUGGING PLAYBOOK (INTERVIEW KILLER)
Task
You are given:
- Spark UI screenshots
- Logs snippets
Explain:
- Root cause
- Evidence from UI
- Fix
- Prevention strategy
➡ This is exactly how senior interviews test
9.15 INTERVIEW QUESTION BANK (MODULE 9)
Must-Answer
- How do you debug slow Spark jobs?
- Which Spark UI tab is most important?
- How to detect skew?
- How to debug executor OOM?
Killer Question
❓ “Explain how you debug a Spark job end-to-end in production”
🧠 ONE-LINER (INTERVIEW GOLD)
Spark UI tells you what is wrong, logs tell you why.
✅ MODULE 9 COMPLETE
You now:
✔ Debug Spark like a production engineer
✔ Read Spark UI confidently
✔ Identify real root causes
✔ Pass scenario-based interviews
🚀 NEXT MODULE OPTIONS
Choose next:
1️⃣ Module 10 — Spark Structured Streaming (State, Checkpointing, Exactly-once)
2️⃣ Module 10 — AWS EMR + Spark (Production Deployment)
3️⃣ Printable Spark Debugging Cheat Sheet
💡 Strong Recommendation:
➡ Module 10 — AWS EMR + Spark (this completes the PySpark-on-AWS story)
Say “Start Module 10” 🔥
Excellent.
Module 10 is where batch-only engineers become real-time data engineers.
Structured Streaming is heavily tested and widely used in production (fraud, logs, CDC, metrics).
📘 MODULE 10 — SPARK STRUCTURED STREAMING (PRODUCTION GRADE)
State · Checkpointing · Exactly-Once · Failure Recovery




🎯 MODULE 10 GOALS
By the end of this module, you will:
- Understand how Structured Streaming really works
- Explain exactly-once semantics clearly
- Design fault-tolerant streaming pipelines
- Debug state, lag, and late data issues
- Answer senior-level streaming interview questions
10.1 Streaming Before Spark (WHY THIS EXISTS)
Old World (Spark Streaming – DStreams)
- RDD-based
- Manual state handling
- Hard to reason about
- Error-prone
New World — Structured Streaming
Streaming as unbounded DataFrames
Built on:
- Spark SQL
- Catalyst optimizer
- Same APIs as batch
➡ One engine for batch + streaming
🔥 Interview Trap
❓ “Is Structured Streaming real-time?”
✅ No — it is micro-batch, not millisecond real-time.
10.2 Core Mental Model (VERY IMPORTANT)


Structured Streaming treats a stream as an infinite table.
Each micro-batch:
- New rows arrive
- Query runs
- Results updated
Key Insight (Interview Gold)
If you understand batch Spark SQL, you already understand Structured Streaming.
10.3 Streaming Architecture (END-TO-END)
Components
- Driver: schedules micro-batches
- Executors: process data
- Source: Kafka / files / Kinesis
- Sink: S3 / DB / Kafka
- Checkpoint store: HDFS / S3
🔥 Interview Trap
❓ “Does each micro-batch create a new Spark job?”
✅ Yes.
10.4 Sources & Sinks (PRODUCTION REALITY)
Common Sources
- Kafka (most common)
- File source (S3/HDFS)
- Socket (testing)
Common Sinks
- File / Parquet
- Kafka
- ForeachBatch (custom logic)
🔥 Interview Trap
❓ “Can JDBC be used as streaming sink?”
✅ Only via foreachBatch.
10.5 Output Modes (INTERVIEW FAVORITE)


Output Modes
| Mode | Meaning |
|---|---|
| Append | Only new rows |
| Update | Changed rows |
| Complete | Full result |
Rules
- Aggregations → Update / Complete
- Non-aggregations → Append
🔥 Interview Trap
❓ “Why append mode fails with aggregation?”
✅ Aggregation updates existing rows.
10.6 State & Stateful Operations (CRITICAL)


What is State?
Intermediate results Spark must remember:
- Aggregations
- Window operations
- Deduplication
Where State Lives
- State Store on executors
- Backed by checkpoint storage
🔥 Interview Trap
❓ “Is state stored in driver?”
✅ No — executor-side state store.
10.7 Checkpointing (NON-NEGOTIABLE)

What Checkpoint Stores
- Offsets (Kafka)
- State store metadata
- Progress info
Why Checkpointing Is Mandatory
Without it:
- No recovery
- Duplicate processing
- Data loss
🔥 Interview Trap
❓ “Can we change checkpoint location?”
✅ No — changing it means new application.
10.8 Exactly-Once Semantics (MOST ASKED)
❌ Wrong Understanding
Spark guarantees no duplicates everywhere.
✅ Correct Understanding
Spark guarantees exactly-once processing semantics between source, state, and sink if sink is idempotent or transactional.
Kafka Example
- Source offsets tracked
- State checkpointed
- Sink committed after success
🔥 Interview Trap
❓ “Is Spark streaming exactly-once?”
✅ Depends on sink behavior.
10.9 Event Time vs Processing Time (VERY IMPORTANT)

Processing Time
- When Spark sees data
Event Time
- When event actually happened
Why Event Time Matters
- Late data
- Out-of-order events
- Accurate analytics
10.10 Watermarking — HANDLING LATE DATA


Example
.withWatermark("event_time", "10 minutes")
Meaning
- Accept late data up to 10 minutes
- Drop anything older
🔥 Interview Trap
❓ “What happens to data older than watermark?”
✅ It is dropped.
10.11 Windowed Aggregations (REAL USE)
.groupBy(
window(col("event_time"), "5 minutes"),
col("user_id")
).count()
Internals
- Stateful
- Requires checkpoint
- Shuffle + state store
10.12 FAILURE SCENARIOS & RECOVERY (PRODUCTION)
Scenario 1 — Driver Crash
- Restart application
- Uses checkpoint
- Resumes from last committed offsets
Scenario 2 — Executor Crash
- State recomputed
- Tasks retried
- No data loss
Scenario 3 — Duplicate Data
Cause:
- Non-idempotent sink
Fix:
- Deduplication
- Transactional sink
10.13 PRODUCTION USE CASE — REAL-TIME LOG PIPELINE
Scenario
- Kafka → Spark → S3
- Aggregations per minute
- SLA-critical
Design
- Event-time windows
- Watermark
- Exactly-once sink
- Stable checkpoint
10.14 MINI PROJECT — STREAMING DESIGN (INTERVIEW STYLE)
Task
Design a streaming job that:
- Reads from Kafka
- Aggregates per user
- Handles late data
- Recovers from failure
Explain:
- Output mode
- State handling
- Checkpointing
- Failure recovery
➡ Exactly how interviews test streaming
10.15 INTERVIEW QUESTION BANK (MODULE 10)
Must-Answer
- Structured Streaming vs DStreams?
- What is checkpointing?
- Event time vs processing time?
- What is watermark?
Killer Question
❓ “Explain exactly-once semantics in Spark Structured Streaming”
🧠 ONE-LINER (INTERVIEW GOLD)
Structured Streaming is Spark SQL running repeatedly on an unbounded table with state managed via checkpointing.
✅ MODULE 10 COMPLETE
You now:
✔ Understand Structured Streaming internals
✔ Design fault-tolerant pipelines
✔ Handle late data correctly
✔ Pass streaming interview rounds
🚀 NEXT MODULE OPTIONS (AWS FOCUS NOW)
Choose next:
1️⃣ Module 11 — Spark on AWS EMR (Cluster, S3, Tuning, Cost)
2️⃣ Module 11 — Glue Streaming + Spark
3️⃣ Printable Structured Streaming Cheat Sheet
💡 Strong Recommendation:
➡ Module 11 — Spark on AWS EMR (this completes PySpark-on-AWS mastery)
Say “Start Module 11” 🔥